UUID V4 Benchmark
UUID V4 is one of many kinds of UUID used as identities for its randomness and uniqueness. In this post I will show some benchmarks of UUID V4 generations in some programming languages. This microbenchmark will measure time spent generating 1 millions UUID. The code is simple, loop for 1 millions time and generate UUID inside. I use benchmarking tools in each languages, except C.
The machine spec for running this benchmark is:
OS: macOS 13.6 x86_64
Host: MacBookPro16,2
CPU: Intel i5-10 (8) @ 2.00GHz
Memory: 16GB
C#
dotnet version: 9
Benchmarked with BenchmarkDotnet version v0.13.12.
The benchmark setting is 10 warmup iterations and 10 measurement iterations.
...
public class UUIDBenchmark
{
private readonly Consumer consumer = ;
public void
{
for
}
}
...
Result: 280.4ms
)
)
)
IterationCount=10 WarmupCount=10
| | | | | |
| |||||
| | | | | |
Java
OpenJDK version 11, 17, 21, 23.
Benchmarked with JMH 1.37
The benchmark setting is 10 warmup iterations and 10 measurement iterations.
...
private int iterations;
public void
...
Result:
Java 11: 230.76ms
)
Java 17: 231.51ms
)
Java 21: 238.43ms
)
Java 23: 227.97ms
)
All of 4 versions are close within 200ms benchmarks. On average around 232ms.
Go
Go version 22 and 23.
Benchmarked using built in tool.
The benchmark setting is 10 iterations.
As far as I know, there's no warming up in Go benchmarking built-in tool.
Libraries used:
- uuid: https://github.com/google/uuid
- fastuuid: https://github.com/rogpeppe/fastuuid
- go.uuid: https://github.com/satori/go.uuid
...
const iterations = 1_000_000
func BenchmarkGoogleUUID(b *testing.B)
func BenchmarkFastUUIDRandom(b *testing.B)
func BenchmarkFastUUIDNotRandom(b *testing.B)
func BenchmarkSatoriUUID(b *testing.B)
...
Note
BenchmarkFastUUIDNotRandom is not random because it only generate next uuid that only differs for the first 8 bit. It's faster, but not secure.
Result:
Go 1.22.0:
Go 1.23.4:
Javascript/NodeJS
NodeJS version 23.4.0.
Benchmarked with benchmark 2.1.4
Libraries tested built-in crypto and uuid 9.0.1.
;
// const { v4: uuidv4 } = require('uuid'); /// for uuid
;
;
suite
'Generating UUID V4 1 million times', ,
'cycle',
'complete',
;
I use let consume; to prevent optimization by the runtime for unused values returned from uuid computation. Async is turned off just like other benchmarks.
Result:
Native crypto: 188.09ms
)
uuid: 157.56ms
)
Ruby
Ruby version 3.2.2.
Benchmarked using benchmark-ips.
$consume = nil
for i in 1..1_000_000 do
$consume = SecureRandom.uuid
end
end
Benchmark.ips do
bench.config(
iterations: 10,
time: 10,
warmup: 10,
)
bench.report() { generate_uuids }
bench.compare!
end
Just like in JS, I use that global to avoid optimization by the runtime for unused values returned from uuid computation.
Result:
) )
) )
) )
) )
) )
) )
) )
) )
) )
) )
Average: 2.3s
Python
Python version 3.13.1
Benchmarked using timeit
= None
=
=
=
=
=
= /
Result: 2.6s
Rust
Cargo version 1.83.0.
Benchmarked with Criterion 0.5.
Library used is uuid benchmarked for both default and fast-rng feature.
use ;
use Uuid;
criterion_group!
criterion_main!;
Result:
- Default feature(using OS RNG): 1.06s
)
fast-rngfeature: 17.81ms
)
C
Clang version 16.0.0.
Using library uuid4
I don't use any benchmarking library since C is compiled, raw and nothing much from the compiler. It's just plain C.
...
int uuid_generated = 1000000;
int i;
char uuid_buf;
float elapsed;
;
for
elapsed = ;
;
...
Result: 107.87ms
Summary
I run all the benchmarks using the benchmarking tools found in each language. In C#, Java, and Rust I use kind of consume, which eliminate compiler/runtime dead-code elimination. It's one kind of compiler optimization for unused values, so I put the values returned inside the consume function/method.
For other benchmarks without consume functions, I use something similar like in Go using runtime.KeepAlive, or using global variable to put values into.
Since values returned are kind of randomized, the constant folding from putting inside global var should be eliminated.
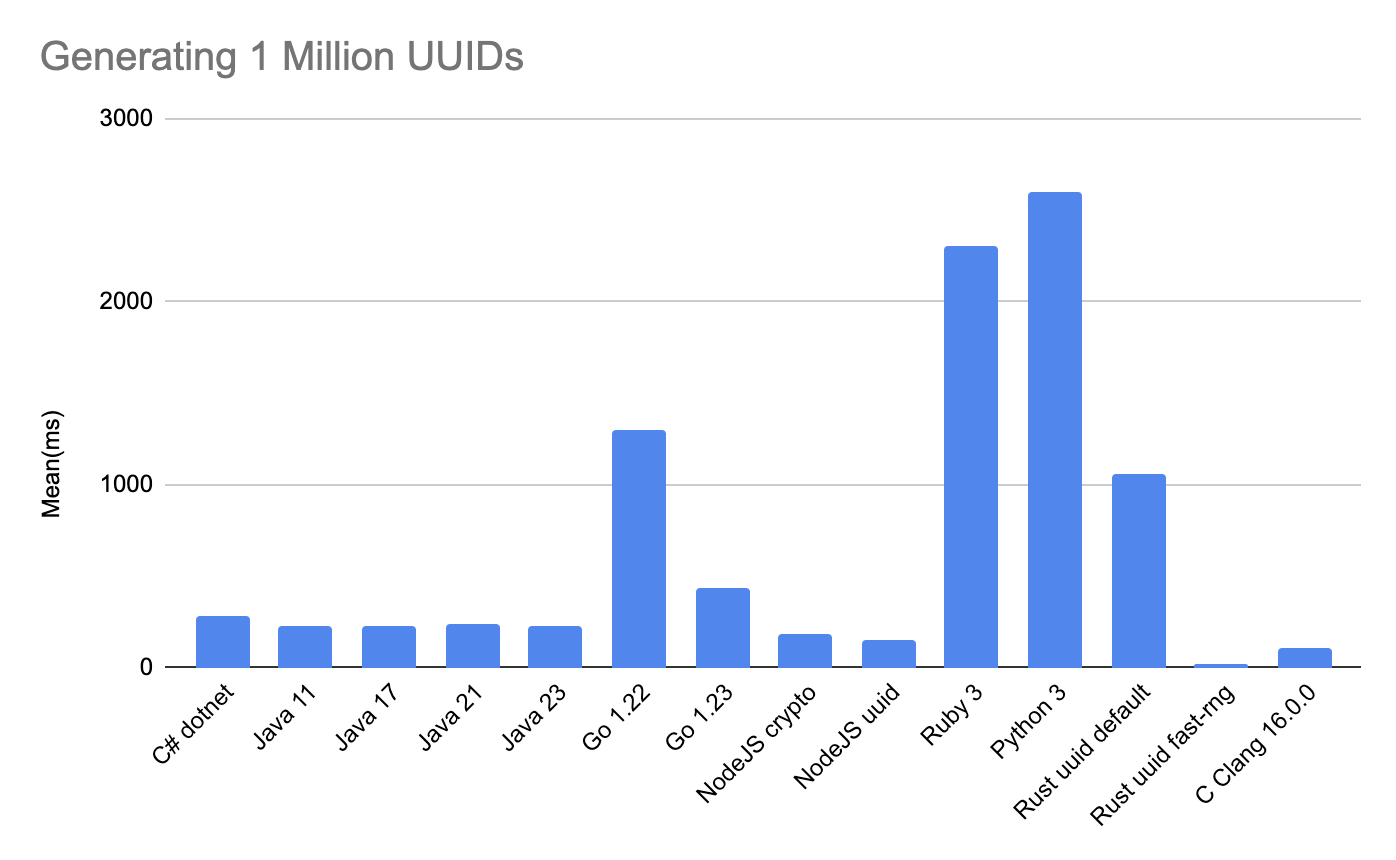
From the results we can see the winner is Rust with fast-rng feature running for 17.81ms. Feature fast-rng use rand crate, while default one use getrandom crate inside. Crate getrandom get the random values from system resource(syscall).
Go happen to increase in performance from 1.22 to 1.23 with 2-3 times improve. All libraries in 1.22 result around 1.30s and 437.33ms in 1.23. Generating with fastuuid(not random) is the fastest for Go, but I won't consider it since it's not random and less secure.
| Language | Mean |
|---|---|
| C# | 280.4ms |
| Java 11.0.25 | 230.76ms |
| Java 17.0.13 | 231.51ms |
| Java 21.0.5 | 238.43ms |
| Java 23.0.1 | 227.97ms |
| Go 1.22 uuid | 1.28s |
| Go 1.22 fastuuid(random) | 1.34s |
| Go 1.22 go.uuid | 1.30s |
| Go 1.22 fastuuid(not random) | 49.94ms |
| Go 1.23 fastuuid(not random) | 51.26ms |
| Go 1.23 uuid | 412ms |
| Go 1.23 fastuuid(random) | 485ms |
| Go 1.23 go.uuid | 415ms |
| NodeJS 23.4.0 crypto | 188.09ms |
| NodeJS 23.4.0 uuid | 157.56ms |
| Ruby 3.2.2 | 2.3s |
| Python 3.13.1 | 2.6s |
| Rust 1.83.0 uuid default | 1.06s |
| Rust 1.83.0 uuid fast-rng | 17.81ms |
| C Clang 16.0.0 | 107.87ms |
This microbenchmark only show a fraction of realtime long running systems. There could be more adjustments/optimizations happening depends on workload and runtime configurations, expecially in languages running on top of virtual machines like C# and Java. There are many other considerations beside microbenchmark for whole big system. This atleast show performance of litle part of system which used to be in contentions specially for CPU bound operations.